RISC is an abbreviation of Reduced Instruction Set Computer. RISC processor has ‘instruction sets’ that are simple and have simple ‘addressing modes’. A RISC style instruction engages “one word” in memory. Execution of the RISC instructions are faster and take one clock cycle per instruction.
Although the forerunners of RISC computers were seen in 1960. But, due to the popularity of CISC microprocessors which were implemented by the manufacturers in calculators, video games, stereos, etc; RISC architecture was overshadowed. According to modern concept dates RISC computers were particularly introduced in the 1980s.
In this section, we will discuss the architecture, instruction set, pipelining, advantages and disadvantage of the RISC processors.
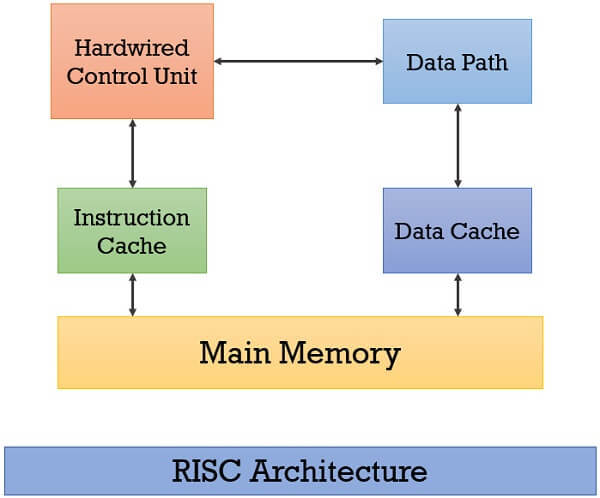
RISC processor is implemented using the hardwired control unit. The hardwired control unit produces control signals which regulate the working of processors hardware. RISC architecture emphasizes on using the registers rather than memory.
This is because the registers are the ‘fastest’ available memory source. The registers are physically small and are placed on the same chip where the ALU and the control unit are placed on the processor. The RISC instructions operate on the operands present in processor’s registers.
Below we have the block diagram for the RISC architecture.
Observe one thing here, we don’t have the “microprogram control store” or the “control memory” like we have seen in the CISC architecture in our previous content.
It is just because all instructions in RISC are simple and execute one instruction per cycle. So, here the instructions are hardwired and there is no need for control store. For each operation, we will have as defined hardwire. Making an instruction hardwired is making a function or operation in instruction permanent using connected circuits.
RISC instructions are simple and are of fixed size. Each RISC instruction engages a single memory word. RISC instructions operate on processor registers only. The instructions that have arithmetic and logic operation should have their operand either in the processor register or should be given directly in the instruction.
Like in both the instructions below we have the operands in registers
Add R2, R3
Add R2, R3, R4
The operand can be mentioned directly in the instruction as below:
Add R2, 100
But initially, at the start of execution of the program, all the operands are in memory. So, to access the memory operands, the RISC instruction set has Load and Store instruction.
The Load instruction loads the operand present in memory to the processor register. The load instruction is of the form:
Load destination, Source
Example Load R2, A // memory to register
The load instruction above will load the operand present at memory location A to the processor register R2.
The Store instruction stores the operand back to the memory. Generally, the Store instruction is used to store the intermediate result or the final result in the memory. It is of the form:
Store source, destination
Example Store R2, A // register to memory
The Store instruction above will store the content in register R2 into the A a memory location.
You can observe that in the example of Load and Store instruction operand side of both instructions appears the same as R2, A. But, the source and destination order of Store instruction is reversed in Load instruction.
RISC instruction has simple addressing modes. Below we have a list of RISC instruction type addressing modes. Let us discuss them one by one.
Immediate addressing mode: This addressing mode explicitly specifies the operand in the instruction. Like
Add R4, R2, #200
The above instruction will add 200 to the content of R2 and store the result in R4.
Register addressing mode: This addressing mode describes the registers holding the operands.
Add R3, R3, R4
The above instruction will add the content of register R4 to the content of register R3 and store the result in R3.
Absolute addressing mode: This addressing mode describes a name for a memory location in the instruction. It is used to declare global variables in the program.
Integer A, B, SUM;
This instruction will allocate memory to variable A, B, SUM.
Register Indirect addressing mode: This addressing mode describes the register which has the address of the actual operand in the instruction. It is similar to pointers in HLL.
Load R2, (R3)
This instruction will load the register R2 with the content, whose address is mentioned in register R3.
Index addressing mode: This addressing mode provides a register in the instruction, to which when we add a constant, obtain the address of the actual operand. It is similar to the array of HLL.
Load R2, 4(R3)
This instruction will load the register R2 with the content present at the location obtained by adding 4 to the content of register R3.
As we know the RISC instructions are simple and engage one word in the memory. Even the ‘location of operands’ within the’ word’ is the same for the different instructions. Among all the instruction the Load and Store are the operations that accesses memory operand.
Most of the RISC instructions are register to register. If we consider the arithmetic and logic instructions, then we have two stages as follow:
Instruction Fetch (IF): Fetching the instruction
Instruction Execute (IE): ALU operation with the register
If we are considering the Load and Store instruction i.e. register to memory or memory to register, then three stages are required as follow.
Instruction Fetch (IF): Fetching the instruction
Instruction Execute (IE): Calculate memory address
Memory Store (M): register to register operation or memory to memory operation
Now consider the following instruction:
Creating a RISC instruction set for the above instruction will be.
Load R1, B
Load R2, C
Add R3, R2, R1
Store R3, C
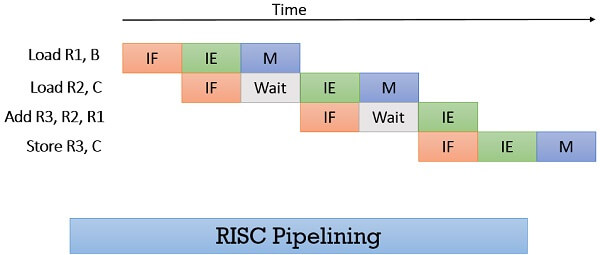
Now in the figure below, we can see how the above RISC instructions are pipelined. The pipelined instructions fasten the execution twice when compared to execution in sequence. The instruction execution stage of first instruction & instruction fetch stage of second instruction is performed parallelly.
Observing the figure we can see that the execute/memory stage of second instruction has to stall till the first instruction memory stage completes. This is the case when we use the single port memory i.e. only one memory access can be done at a time.
The above stalling condition reduces the execution speed. To overcome this, we can use NOOP (No Operation) instruction which can be inserted in the instruction stream by the compiler or assembler.
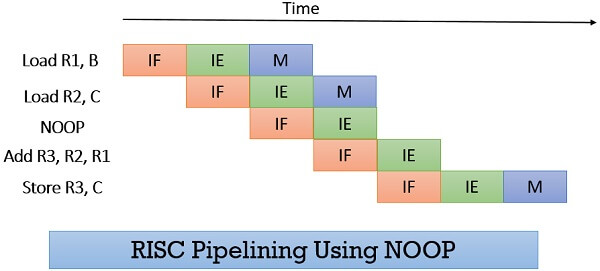
This would speed up the execution as all the stages are of equal duration. But, what if the execution stage is longer, as it ALU operation. In this case, the IE stage is divided in two parts IE1 register reading and IE2 ALU operation.
MIPS, SPARC, IBM POWER instruction set, Alpha, RISC-V, ARM architecture.
This is all about the RISC processor and its instruction set architecture. RISC architecture is now used worldwide in cellular telephones, computer tables and even supercomputers.